
前回の振り返り
パート2では多系列・時系列予測モデルを行うための、特徴量エンジニアリングを行いました。
生成された特徴量は、外生的なものだけでなく、時系列特有の要素を表現していることが重要でした。
Iterativeモデルによる多系列・時系列予測
みなさんこんにちは、NRIのデータサイエンティスト、時系列予測プラクティスチームの鈴木です。
今回は多系列・時系列予測を行うモデル構築の第1弾として、Iterativeモデルを導入していきます。
多系列・時系列予測モデルの概観

Iterativeモデルとは
第1回でご紹介したとおり、多系列・時系列予測を行う際に「一つ一つの時系列に対してモデル適用を繰り返す (Iterative)」方法をIterativeモデルと呼びます。これは「複数の時系列全体に対して一つのモデルを適用する(Global)」とは対比的です。それぞれに優れている点があり、一般にどちらが良いというものでもありません。第3回ではIterativeモデルによる多系列の予測を行います。
Iterativeモデルのメリット:
1. 予測根拠を提示可能
2. モデル改善に取り組みやすい
3. 安定した精度が得られる
4. 時間方向の連続性を自然に扱える(無理なデータ加工が不要)
デメリット:
1. 処理時間が非常に長くなる場合がある
2. 個々の時系列に対してチューニングを行うのが困難
3. 新商品の予測がほぼ不可能(コールドスタート)
定義だけみると、全てのデータを使って学習を行うGlobalモデルのほうが学習効率が良さそうに聞こえますが、時系列予測はそう簡単ではありません。むしろ統計モデルのほうが良い振る舞いをするケースが多々あります。そのためプロジェクトの序盤ではまずIterativeモデルに取り組むべきです。
Iterativeモデルに含まれるアルゴリズムはたくさんあります。古典的なモデルから新しいものまでありますが、基本的にはデータに対し一通り試すのが無難です。時系列データ、特に多系列の予測は本当に難しく、最新の手法一発で解決するというケースは殆どありません。
1つ1つのモデルのチューニングや特徴量作成に入り込む前に、最初にまずは幾つもの手法でざっと予測を立ててみることで、課題を明らかにすることをオススメします。
工程
大まかに多系列・時系列予測は以下の工程に沿って行われます。

実装
前処理までは完了しているとして、モデリングを行うEvaluationの部分の一例です。
上記で紹介したアルゴリズムであれば、基本的にはmodeltimeライブラリの枠組みで扱うことができます。
modeltimeはtidymodelsという汎用パイプラインの枠組みに従います。つまりモデリングは
workflow (コンテナ) %>% add_model (モデルの仕様) %>% add_recipe (データへの当てはめ方)
という形で記述することができます。これを順に用意していきます。
まずはrecipe:
model_spec_list <- list() recipe_list <- list() model_list <- list() ## recipes ---- # regression recipe_list$regression <- recipe( y ~ ., data = extract_nested_train_split(combi) ) %>% step_zv %>% step_dummy(weekNumber) %>% step_fourier(Date, period=52, K=12) # for arimax recipe_list$regression_arima <- recipe( y ~ Date + weekNumber + IsHoliday + ChristmasWeek + TranksgivingWeek, data = extract_nested_train_split(combi) ) %>% step_zv %>% step_dummy(weekNumber) # only date recipe_list$date_only <- recipe( y ~ Date, data = extract_nested_train_split(combi) )
recipeではいわゆるformulaの指定と、one-hot等の定番の変形を行います。
時系列予測に特有な項目として
- formula式の右辺に時間軸情報 (Date) を渡す必要がある (説明変数が取れないモデルでも必要)
- アルゴリズム内部に季節性や周期性を処理する機能がない場合、説明変数として特徴量化する
といった工程が追加されています。
多くのモデル学習で必要になる変形の工程を、1行で見やすく記述できるためオススメです。
tidymodelsで扱えない学習を行う場合でも、前処理だけに利用する、といったことも可能です。
次にmodel部分です。
## model specs ----
model_spec_list$arimax <- arima_reg(
seasonal_period = 52,
seasonal_differences = 1,
non_seasonal_differences = 1
) %>%
parsnip::set_engine("auto_arima")
model_spec_list$stlm_arima <-
seasonal_reg(seasonal_period_1=52) %>%
parsnip::set_engine("stlm_arima")
model_spec_list$stlm_ets <-
seasonal_reg(seasonal_period_1=52) %>%
parsnip::set_engine("stlm_ets")
model_spec_list$tbats <-
seasonal_reg(seasonal_period_1=52) %>%
parsnip::set_engine("tbats")
modeltimeを利用することで、複数のアルゴリズムを試す際にコードを大幅に圧縮することが可能です。
ポイントとして、STLによる季節性分解はseasonal_regで行うことができます。例では
1つ目はいわゆるSARIMAXモデル。
2つ目はSTLで季節性を除去した上で、ARIMAモデルの適用。
3つ目は同じくSTL+ETS
4つ目はTBATS (指数平滑化の一種)
を当てはめています。
あとはこれらを組み合わせてモデルを作成します。
## Model list # SARIMAX model_list$sarima <- workflow() %>% add_model(model_spec_list$arimax) %>% add_recipe(recipe_list$regression) # STL + ARIMA model_list$stlm_arima <- workflow() %>% add_model(model_spec_list$stlm_arima) %>% add_recipe(recipe_list$date_only) # STL + ETS model_list$stlm_ets <- workflow() %>% add_model(model_spec_list$stlm_ets) %>% add_recipe(recipe_list$date_only) # tbats model_list$tbats <- workflow() %>% add_model(model_spec_list$tbats) %>% add_recipe(recipe_list$date_only)
最後に実行例です。iterativeモデルの場合、実行はmodeltime_nested_fitを通して行います。
この処理にはそれなりに時間を要します。実行時間が非常に長いアルゴリズムだと、モデル改善に使える時間が減ってしまうため、
精度だけでなく実行時間も含めてアルゴリズムを検討すべきです。
model_tbl_lst <- list()
model_tbl_lst$sarima <- combi %>%
modeltime_nested_fit(
model_list = list(model_list$sarima),
control = control_nested_fit(
verbose = TRUE,
allow_par = TRUE
)
)
第1回でご紹介したとおり、エラーを確認してみましょう。
series is not periodic or has less than two periods
系列長が短すぎて、季節分解ができないものがあるようです。 iterativeモデルは系列同士でお互いに影響したりはしないので、適切な系列を選ぶ工程を加えたほうが良さそうですね。
学習の内容を確認したいところですが、先にSubmitを済ませてスコアを確認してみましょう。
上記のモデルはcalibrationされたデータに対する学習なので、未知の将来予測を行うために、全量データでの再学習を行います。
これはmodeltime_nested_refitを適用すればすぐに実行できます。
refit_model_lst <- map(model_tbl_lst, ~ {
modeltime_nested_refit(
.x,
control = control_refit(
verbose = TRUE,
allow_par = TRUE
)
)
})
iterativeモデルでは予測できないデータ点があります。
(学習期間にIDがない、過去の系列長が短いなど)
ここでは一旦ゼロで埋めて提出してみましょう。
fcst_lst <- map(refit_model_lst, extract_nested_future_forecast)
fcst_tbl <- list()
for(i in 1:length(refit_model_lst)) {
method_name <- names(refit_model_lst)[[i]]
fcst_tbl %<>% c(list(
refit_model_lst[[method_name]] %>%
extract_nested_future_forecast %>%
mutate(source = method_name) %>%
mutate(.model_id = i)
))
}
fcst_tbl %<>% bind_rows
submit_fcst <- fcst_tbl
submit_fcst %<>% mutate(.value = .value ^ 2)
submit_fcst %<>%
mutate(Id = paste(Id, .index, sep = "_")) %>%
select(.model_id, source, Id, .value) %>%
nest(df = c(Id, .value))
submit_fcst$df %<>%
map(~ {
submission %>%
select(Id) %>%
left_join(.x, by="Id") %>%
mutate(Weekly_Sales = if_else(
not_na(.value), .value, 0
)) %>%
select(Id, Weekly_Sales)
})
submit_fcst %>%
pwalk(function(.model_id, source, df){
write_csv(
df,
str_glue('reports/submission_{.model_id}_{source}.csv')
)
})
| private | public | |
|---|---|---|
| 1.sarima | 3,032 | 2,919 |
| 2.stlm_arima | 2,911 | 2,786 |
| 3.stlm_ets | 2,945 | 2,819 |
| 4.tbats | 3,442 | 3,250 |
| 0.snaive | 3,026 | 2,944 |
STL+ARIMAモデルの精度が頭1つ抜けて良さそうですね。STL+ETSも実行時間が速い割に優れています。順位としては
98 / 688 チーム
SNAIVEが170位相当なので、かなり改善しましたね。
予測改善の方向性について
上記では全体を1つのiterativeモデルで予測することを考えました。もう少し細かく見ていきましょう。
calibrationの結果を使います。
id_samples <- withr::with_seed(123, {
sample(unique(model_tbl_lst$sarima$Id), size=6)
})
model_tbl_lst$sarima %>%
extract_nested_test_forecast() %>%
filter(Id %in% id_samples) %>%
group_by(Id) %>%
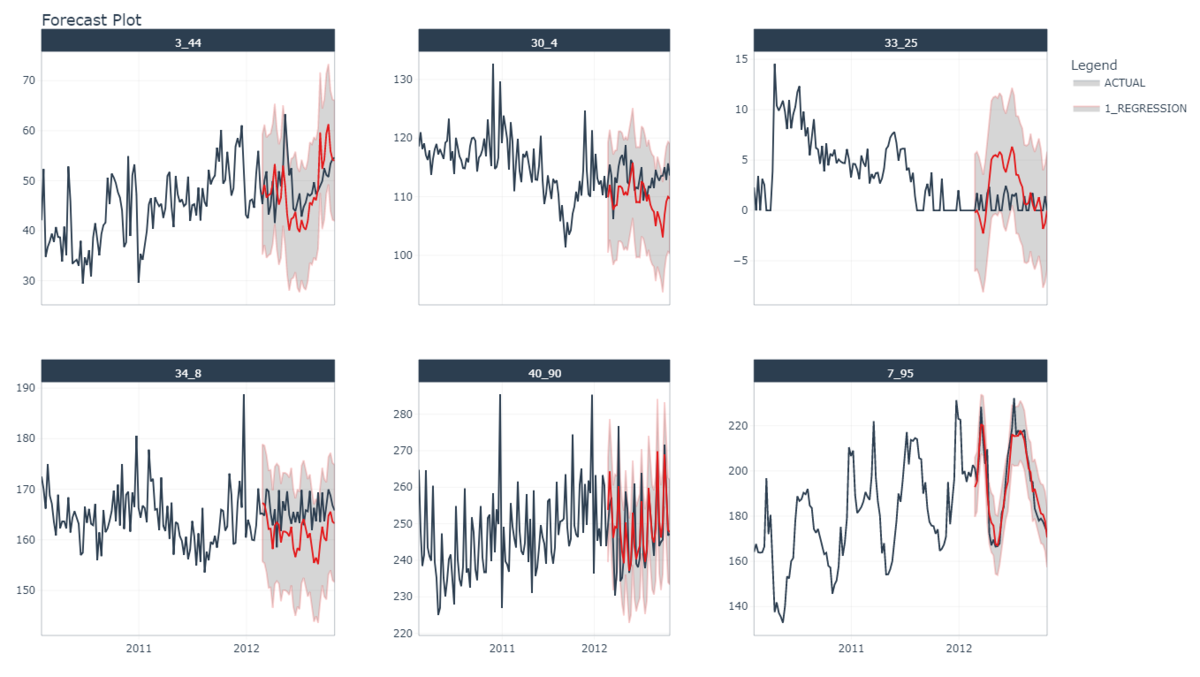
plot_modeltime_forecast(.facet_ncol = 3)
SARIMAXだけピックアップしたとき、系列によって当てはまりの良さに大きな違いがあることに気付きます。
強い周期性がある40_90や7_95に対する予測は非常に良いです。 一方で値がゼロ付近を走る33_25での予測はよくありません。
他のモデルを見てみましょう。
test_acc <- list()
for(i in 1:length(model_tbl_lst)) {
method_name <- names(model_tbl_lst)[[i]]
test_acc %<>% c(list(
model_tbl_lst[[method_name]] %>%
extract_nested_test_accuracy() %>%
mutate(source = method_name) %>%
mutate(.model_id = i)
))
}
test_acc <- bind_rows(test_acc)
test_acc %>%
select(Id, .model_id, source, mape) %>%
filter(complete.cases(.)) %>%
group_by(.model_id, source) %>%
summarize(q25 = quantile(mape, probs = .25),
q50 = quantile(mape, probs = .5),
q75 = quantile(mape, probs = .75)
)
calibration全体では、Kaggleスコアと同様に、STL+ARIMA, STL+ETSが良さそうです。
| .model_id | source | q25 | q50 | q75 |
|---|---|---|---|---|
| 1 | sarima | 4.75 | 7.81 | 16.66 |
| 2 | stlm_arima | 4.37 | 6.88 | 13.47 |
| 3 | stlm_ets | 4.38 | 6.89 | 13.90 |
| 4 | tbats | 4.56 | 7.32 | 15.75 |
しかしこれを局所的にみると、違う結果が見えてきます。先程グラフにした6枚について調べてみると
test_acc %>% filter(Id %in% id_samples) %>% select(Id, source, mae) %>% pivot_wider(names_from=source, values_from=mae)
| Id | sarima | stlm_arima | stlm_ets | tbats |
|---|---|---|---|---|
| 3_44 | 4.50 | 5.56 | 5.62 | 3.24 |
| 7_95 | 5.08 | 7.11 | 7.15 | 7.16 |
| 30_4 | 3.99 | 4.00 | 4.07 | 4.78 |
| 33_25 | 2.31 | 2.34 | 2.35 | 2.18 |
| 34_8 | 5.23 | 5.76 | 5.72 | 5.54 |
| 40_90 | 5.15 | 7.73 | 7.00 | 11.34 |
※ ここでのMAEは、売上に対して平方根を取ったところで計算しています。
全体とは真逆の結果になってしまいました。これらの系列に対しては、SARIMAXやTBATSの方がが優れています。
多系列予測の難しくも面白いところはこういったあたりにあります。iterativeモデルの場合、全ての系列に対して良く振る舞うモデルはなく、各系列で使い分けたり、特別に調整する必要があります。
実務では全体のスコアだけ見ていても改善点は見えてこないので、1つ1つの系列に目を通していく泥臭い作業です。
上記のようなギャップは、たいていの場合、ごく一部の系列で大きなエラーが発生していることで引き起こされています。
iterativeモデルでもまだ改善できるところはありそうですが、多系列予測の大枠を紹介するため、次回はGlobalモデルについて見ていきたいと思います。