
Part2 特徴量エンジニアリング
前回の振り返り...
パート1では、実践的な多変量時系列予測モデルを構築するためのアプローチを紹介し、過去のKaggleコンペティション のデータセットを用いて、ベースラインとなるSeasonal Naiveモデルを作成しました。 今回のパート2では特徴量エンジニアリングを扱います。
時系列データの特徴量エンジニアリング
NRIデータサイエンスブログへようこそ!NRIのデータサイエンティスト、時系列予測プラクティスチームのSatyakiです。
パート2では、特徴量エンジニアリング、特に時系列のMLモデルのトレーニングに使用される特徴量について説明します。 ARIMAやExponential Smoothingなどの伝統的な時系列モデルと異なり、機械学習モデルはクロスセクションデータを用いて学習させるため、それぞれの学習用サンプルは独立していると考えられます。したがって、ML時系列予測モデルの性能は、与えられる特徴量の質とクロスバリデーションの適切さに大きく依存します。
データをもう一度見てみましょう。各店舗と部門の組み合わせの売上高の時系列となっています。

日付に関するデータだけで、以下のような複数の時系列特徴量を作成することができます。

上記のように、DateとIsHolidayのカラムから、37個の時系列特徴量を作成することができます。さらに、平均や標準偏差をエンコーディングし、より多くの特徴量を追加します。
今回のモデルで使用する特徴量について少し詳しく説明します。
- 時系列特徴量(今回生成したもの) :
- 1.a. Time lags - 自己回帰を捕捉する特徴量。
- 1.b. Rolling means - 時系列のトレンドを捉える特徴量。
- 1.c. Date features - 複数の季節性を捉えるために、月、四半期、週のような特徴量。
- 1.d. Holiday features - 祝日に関する特徴量。
- 1.e. Target Encoding
- 外生変数 (コンペから取得したもの)
1.時系列特徴量
1.a. Time Lags
売上データなどの時系列データの多くは、時間依存性を持っています。ある日の売上はその日の前日、先週、先月の売上に依存します。よって、自己回帰的な特徴量は時系列の重要な特徴量の1つとなっています。それでは、どのラグをモデルに含めるかの説明をしていきます。


一番上のグラフから、売上のパターンが1年周期でみられることが分かります。これは、ラグ7,8とラグ51-53でスパイクを示すACF(自己相関関数)をプロットすることでも確認できます。ACFのプロットは、時系列におけるラグ間の相関を求めるのに使われます。今回予測期間は39週間であり、非回帰MLモデルなので、ラグ39から53のみを使用することにします。たとえより広いレンジのラグを使用できたとしても、大きなラグの値まで使用すると、NAが多くなってしまうので、注意が必要です。それを踏まえ、今回はラグ53までしか使用しないことにしました。
1.b. Rolling Means
時系列のトレンド成分は、時系列の平均における持続的で長期的な変化を表します。移動平均をプロットすることで、時系列がどのようなトレンドを持っているかを見ることができます。実際に時系列の移動平均を計算するには、定義されたある幅の値の平均を計算する必要があります。グラフ上の各点は、左側のある一定の幅の中にある値の平均となっています。この操作によって、短期的な変動を滑らかにし、長期的な変化のみを残すことが出来ます。

上の図のように、短期的な変動が抑えられ、長期的な変化を捉えることが出来ています。移動平均の特徴量とともに、複数のウィンドウの移動標準偏差についても同様にプロットします。

1.c. Date Features
日付の特徴量は、ラグとともに、モデルに季節性の情報を追加したものです。複数の季節特徴量をモデルに組み込み、正則化を通して最適な特徴量を選択しました。
- 月、四半期、週番号は、複数の季節のパターンを捉えるための重要な特徴量となっています。


- 周期性を持つ特徴量のエンコーディング: 週、月、季節などの時系列特徴量はもともと周期性を持つため、その周期的な意味合いを残したいと思います。それぞれの時系列特徴量を、単調ではなく、また周期の最初と最後の値に乖離がないような二つの特徴量に変換します。
下の図は、時計の動きが三角関数曲線へどのようにエンコードされるかを示しています。月や年についても同様に三角関数曲線へ変換します。
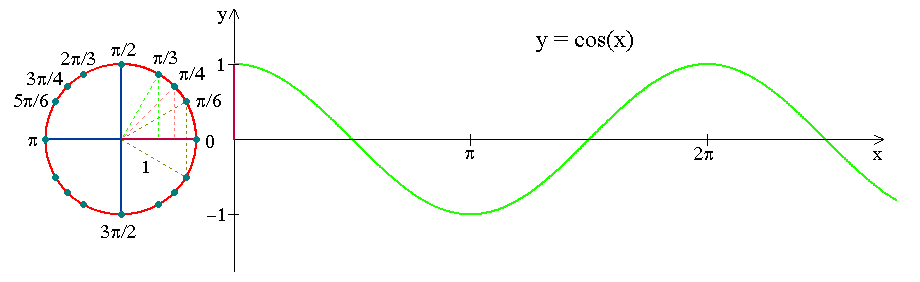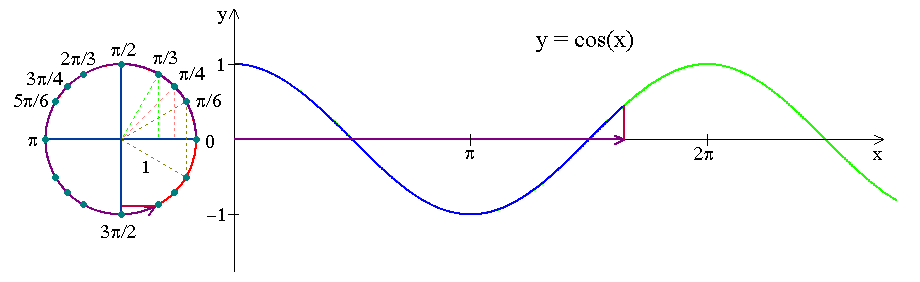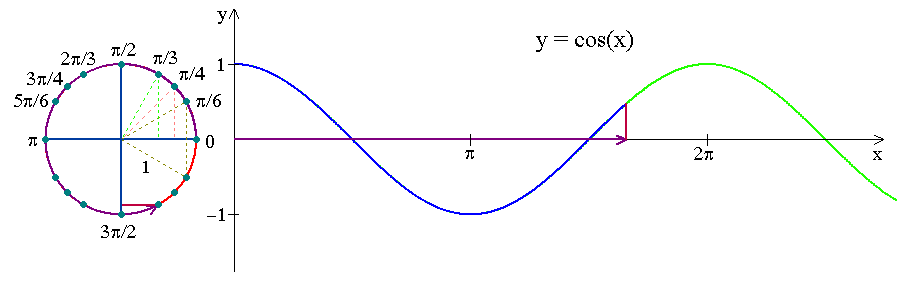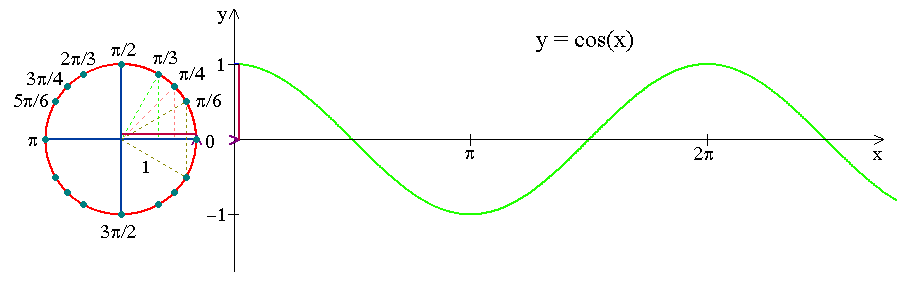
下のsinとcosの曲線は、月次の周期性を捉えています。:


下のsinとcosの曲線は、年の周期性を捉えているので、月次のものより波長が長くなっています。


1.d. Holiday Features
評価指標において、祝日週の予測エラーのポイントが通常週と比べて5倍重みを与えていることから、祝日はコンペにおいて非常に重要な要素であると言えます。つまり、売上が急増するクリスマスやサンクスギビングの日のスパイクを予測することが非常に重要になるのです。
Walmartは、スーパーボウル、労働者の日、サンクスギビング、クリスマスの4大祝日に向けて、値引きキャンペーンを行っています。以下の日付は、コンペから入手可能なものです。
- Super Bowl: 12-Feb-10, 11-Feb-11, 10-Feb-12, 8-Feb-13
- Labor Day: 10-Sep-10, 9-Sep-11, 7-Sep-12, 6-Sep-13
- Thanksgiving: 26-Nov-10, 25-Nov-11, 23-Nov-12, 29-Nov-13
- Christmas: 31-Dec-10, 30-Dec-11, 28-Dec-12, 27-Dec-13
下のプロットは、祝日の特徴量となっています。

皆さんご存じの通り、祝日が売上に与える影響というのはその日だけでなく、クリスマスやサンクスギビングの前にギフトを購入する人が多いため、その数日前にも影響します。そこで、そのようなトレンドを把握するために、2つの特徴量(祝日の数日後と数日前)を作成しました。


また、数日前後だけではなく、その一か月前後に対しても影響を与えているかどうか確かめる必要があります。そこで、以下のような特徴量を作りました。


このように祝日の効果を複数の方法でエンコードすることで、モデルの大幅な性能向上が期待できます。
1.e. Target Encoding
カテゴリ変数の値を、予測しようとしているターゲット変数の数値(平均値)へ置き換えるプロセスのことを指します。このプロセスはオーバーフィッティングにつながってしまう可能性があります。特に時系列の場合は、将来のデータを使って、過去を予測することは注意する必要があります。したがって、ターゲットエンコーディングを用いてモデルを学習するためには、時系列クロスバリデーションを用います。

上の図はトレーニングセットとテストセットの系列を示しており、青がトレーニングセット、オレンジがテストセットとなっています。トレーニングセットで平均・標準偏差エンコーディングをし、テストセットで試すという方法を複数のトレーニング・テストデータで行うことで、ハイパーパラメータをチューニングしました。今回は平均と標準偏差の特徴量を36グループ作成しました。
以下は、エンコーディングに利用したカテゴリーの一部となっています。
- Store and Dept
- Store, Dept and Holiday
- Store, Dept and Month
- Dept and Christmas week
- .....
このようにして,各店舗と各部門の売上高のベースライン平均をグローバルモデルに組み込みます。

上の図は、同じ部門であっても、店舗によって平均売上が大きく異なることを示しています。(例:Dep.75) このように、エンコーディングによって、グローバル多変量時系列モデルに複数のベースライン特徴量を追加することが出来ます。
2. Exogenous features
コンペティションで与えられる features.csvに含まれていた特徴量は以下の通りです。
- Store - 店舗番号
- Date - 週番号
- Temperature - 各地域の平均気温
- Fuel_Price - 各地連域での燃料費
- MarkDown1-5 - Walmartが実施している値引きキャンペーンに関するデータを特定出来ないようにしたものです。データは2011年11月以降のもので、すべての店舗のデータがあるわけではなく、欠損にはNAが入っています。
- CPI - 消費者物価指数
- Unemployment - 失業率
- IsHoliday - 祝日を含む週であるか、否か
上記のように、クリスマスやサンクスギビングなどの祝日の種類に関する情報もありました。
features.csvの中に入ってる特徴量は、モデルの性能に大きく寄与しそうなものはありませんでしたが、とりあえず残しておくことにしました。
特徴量エンジニアリングはモデルの性能を左右する重要な要素になります。今回のように、外生的な特徴量がモデルの精度にあまり寄与しないことは多いので、時系列データのトレンドやパターンをすべて捉えるためには、特徴エンジニアリングを徹底的にやる必要があります。今回のケースでは、日付と祝日のカラムだけで数十の時系列特徴量を作成することができました。
次回パート3では ...
次回のパート3は、機械学習のテクニックにの話に入る前に、従来の統計的時系列モデルについて見ていきます。Seasonal ARIMA、Expoential smoothing、TBATSなどを使って、最先端のMLモデルと同等、あるいはそれ以上の予測モデルの作成方法を説明する予定です。それでは、また次回のブログでお会いしましょう!